
人类最简单的常识,恰恰是机器人最大的痛点
为什么机器人跳舞“一条龙”,干活“一条虫”,其根本原因是机器人缺乏对基础物理世界的理解,所以在与外界物体交互时,缺乏空间感。并且机器人感知世界的能力还受到其自身传感器的限制。典型的,透明玻璃与高反光金属长期以来被称为 “视觉系统的阿喀琉斯之踵”。传统的 RGB-D 相机与 LiDAR 在面对这些材质时,往往因光线的折射与镜面反射而产生严重的 “盲区” 或 “幻觉”,导致识别困难。
近日,蚂蚁集团旗下具身智能公司蚂蚁灵波发布LingBot-Depth。作为一款面向真实场景的深度补全模型,LingBot-Depth最大的特点是可以通过RGB-D相机让机器人识别玻璃杯等透明物体和金属碗等高反光物体。

在LingBot-Depth论文最后长长的参考清单中,更是展示了研究者们为了让机器人看清上述物体所做的不懈努力。
01.
为什么机器人对透明/高反光物体“视而不见”
受制于传感器原理,机器人的“致盲”本质上是光线传播和传感器假设之间的冲突。常规的深度传感器均假设环境表面为朗伯体(Lambertian),即光线光线向各个方向均匀散射。但这在透明与高反光材质中并不适用。
以机器人常见的双目传感器为例。其工作原理类似人眼,两个镜头从不同角度同时捕获同一物体的图像,系统通过对应点成像的像素差来获取深度信息。但受制于摄像头自身限制,在应对玻璃这些透明材质时,无法匹配有效的像素点,就会导致两路图片过于相似。同理,在面对镜子、金属之类的高反光物体时,两路图片又会发生严重畸变,导致匹配算法失效。反映到信号上,就是输出空洞或者错误的数据。最终被当作噪声处理掉。
因此,看清透明物体和高反光物体一直是机器人领域重要的研究课题。
02.
四种技术路线
为了解决以上问题,研究者们已经提出四种技术路线。
一是主动传感与物理建模结合的技术路线。该路线试图通过改进传感器硬件或引入明确的物理假设来对抗光学挑战。核心机制是利用多频段光波、偏振光或多视角集合约束(比如表面法向一致性)来检测异常反射,并通过物理模型(“透明物体必有折射”)反推真实深度。
但该方案无法彻底解决多路径干扰,对环境光极为敏感。另外,高精度的传感器,比如偏振相机,成本高昂,无法商用落地。
二是深度估算。该路线是利用海量数据训练的强先验模型,直接学习“图像纹理”到“3D几何”的映射,试图通过语义理解来“脑补”透明物体的形状。
该路线最大的优势在于泛化性比较好,不受环境光影响。但估算的精度一般,尤其是如果采用单目视觉的话,需要额外的校准。
三是深度补全,蚂蚁灵波LingBot-Depth便属于这一类。其核心是将稀疏或者噪声严重的深度信息修复为稠密深度。其核心机制是将传感器输入的NaN视为掩码(Mask),利用RGB的边缘和纹理信息进行生成式填充。
该路线的好处是输出值为绝对深度,不需要额外的标定。并且深度贴合RGB图像边缘,解决了“深度膨胀”的问题。但严重依赖原始信号,如果传感器信号出现大面积空洞,补全难度指数级上升。
四是提示与先验融合路线。该路线是利用“提示工程”的思想,将稀疏的几何信号(如Lidar点)作为Prompt,注入到冻结的深度基础模型中。核心机制与NLP 中的 Prompt Tuning类似。模型主体提供强大的语义理解,输入的疏深度点提供尺度锚点(Scale Anchor),两者结合生成高分辨率公制深度。
从描述即可看出,该路线可以实现极高的相对和绝对深度,但需要依赖的模型较大,对提示工程也有这较高的要求。

03.
LingBot-Depth 核心设计与基准表现
具体到LingBot-Depth而言,
核心训练方法为掩码深度建模 (MDM),该框架受到掩码图像建模(如 MAE)的启发,但针对RGB-D 数据进行了调整。
在自然掩码策略上,与传统的MAE采用的随机掩码不同,LingBot-Depth 利用传感器因物理限制(如反光、透明表面)产生的“自然缺失”作为掩码。输入过程中,RGB图像保持完全可见,仅对深度图进行掩码处理。模型利用完整的 RGB 上下文来推断被掩盖的深度信息。总体掩码率控制在60-70%之间。具体的掩码逻辑为,完全缺失深度的 patch 总是被掩盖;包含混合有效/无效值的 patch 有 75% 的概率被掩盖;如果自然缺失不足,则随机采样额外的有效 token 进行掩码。
在模型架构方面,编码器采用的是24 层 ViT-Large作为骨干网络,RGB 图像和深度图通过独立的 Patch Embedding 层处理,然后投影到相同的 2D 网格上。除了空间位置编码外,还引入了模态嵌入 (Modality Embedding),以区分 token 是来自 RGB 还是深度图。解码器放弃了 MAE 中常用的浅层 Transformer 解码器,改用 ConvStack 卷积解码器。这更适合密集几何预测任务,通过多尺度特征金字塔重建全分辨率深度图。

数据方面,模型在1000万个RGB-D样本上进行了训练,数据来源包括三个方面。
100万仿真数据。使用 Blender 渲染,但不同于仅渲染完美深度,该流程模拟了真实主动式相机的成像过程(包括散斑图案),并使用 SGM 算法生成带有自然伪影和缺失的“传感器级”深度图。
200万真实数据,使用包含 Orbbec、RealSense 和 ZED 相机的采集系统,在极其多样化的室内场景中采集。利用立体匹配网络生成伪真值(Pseudo-GT)并进行左右一致性检查。
700万开源数据,整合了 ScanNet++、TartanAir、Hypersim 等 7 个开源数据集。对于这些相对完整的数据,训练时会人为添加高斯噪声和随机掩码。
在 iBims-1、DIODE、ScanNet++ 等公开基准的评测中,LingBot-Depth 展现出了显著的性能优势,特别是在处理 “非朗伯体” 表面的能力上。相比现有最佳方法实现 40–50% 的误差降低。在稀疏 SfM 输入条件下,室内场景 RMSE 降低 47%,室外场景降低 38%。
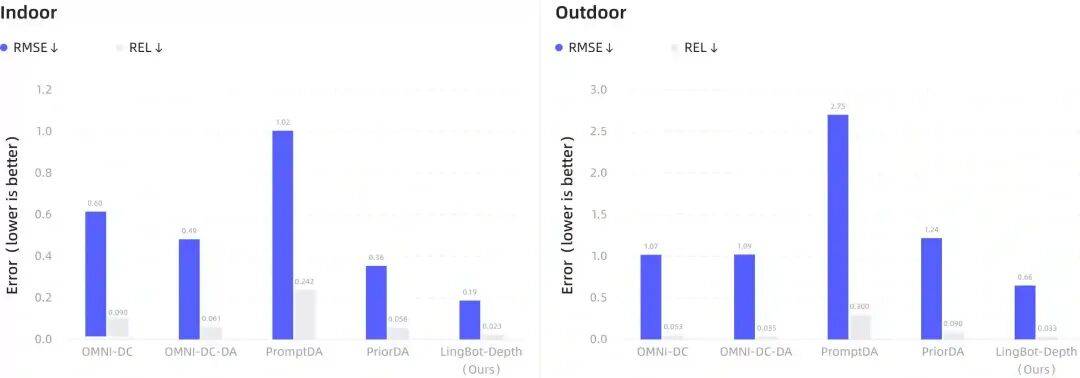
对于机器人操作能力提升方面,使以往无法抓取的物体成为可能——透明收纳箱抓取成功率从 0% 提升至 50%,在多种反光和透明物体上提升 30–78% 的抓取成功率。具体物品中,钢杯:65% → 85%,玻璃杯:60% → 80%,玩具车:45% → 80%。
04.
写在最后
和LingBot-Depth 优异的表现相比,更重要的蚂蚁灵波的开源精神,目前LingBot-Depth 模型完全开源,可复现。客观来说,要让机器人融合人类日常生活还有很长的路要走,而开源的精神势必可以加速前进的步伐。












 沪公网安备31010702008139
沪公网安备31010702008139